어제 초,중급용 머신러닝 로드맵을 알아보고 지금은 Google Colaboratory나 Jupyter에서 기초적인 머신 러닝을 연마해야한다고 생각하지만 오늘은 그냥 좀 가볍게 코드 안 쓰고 공부하고 싶어서(ㅎㅎㅎㅎ) 구글 머신러닝 crash course 웹사이트에서 개념 정리를 해보려고 한다.
그럼 개념 정리 시작~!
주요 머신러닝 용어
- Label(레이블): 우리가 알고자 하는 것, linear regression에서 y 값에 해당
- Features: 인풋, linear regression에서 x 값에 해당, 간단한 머신러닝이라면 하나의 feature이 필요하지만 복잡한 머신러닝 모델이라면 많은 feature 필요.

- Examples: 어떤 특정 상황의 데이터, labeled examples, unlabeled examples로 나뉨
- Labeled Examples: {features, label} : (x, y)
- Unlabeled Examples: {features, ?} : (x, ?)


- Models(모델): 모델은 feature와 label 사이의 관계를 결정한다. 모델은 training과 inference 두가지 단계를 가진다.
- Training(학습) : 모델 학습시키는 단계, 모델에게 labeled examples를 주면서 모델이 feature과 label 사이의 관계를 알아보도록 하는 단계, y’을 찾는 단계.
- Inference(추론) : 모델이 학습을 끝내고 unlabeled examples를 주며 y값인 label을 찾는 것.
- Regression & Classification (회귀분석 & 분류): regression 모델은 continuous한 값 구하는 것(예: 1. 캘리포니아의 집 값은? 2. 유저가 이 광고를 누를 가능성은?), classification 모델은 discrete한 값 구하는 것(예: 1. 이 이메일은 스팸인가 아닌가? 2. 이 이미지는 개인가 고양이인가 햄스터인가?).

머신러닝에 이용되는 Linear Regression

Linear Regression은 보통 y = ax + b의 형태를 띄지만 머신러닝에서는 y’ = w1x1 + b 형태를 띈다. 그냥 y 대신 y’을 쓰고 x 대신 x1을 쓰고 a대신 w1을 쓰는 것 뿐이다. 여기서 y’은 predicted label(레이블, 우리가 찾는 결과 값), b는 bias(편향, b는 종종 w0로 쓰이기도 함), w1은 feature 1의 weight(비중), x1은 feature 1의 값(우리가 모델에게 주는 인풋 값)을 가르킨다.
y’ = w1x1 + b 형태보다 복잡한 머신러닝 모델은 y’ = w1x1 + w2x2 + w3x3 + b 형태를 띈다. 이때는 모델에 3가지 인풋 값을 준 것이다.
모델 학습 시 나오는 Loss Function
- Loss Function: 머신러닝 모델 학습은 그 모델의 올바른 weight(비중)과 bias(편중) 값을 찾는 것을 목적으로 한다. 하지만 이 값들의 추정이 올바르지 않다면 Loss 값이 높아지게 된다. 이상적인 머신러닝 모델은 Loss 값이 0에 수렴하지만 잘못된 학습은 Loss 값을 높아지게 한다.

- Loss Function 예시: Linear Regression 모델에선 Squared Loss (L2 Loss)를 사용한다.

- Square Loss 값을 우리가 사용한 데이터를 기반으로 평균을 내보면 평균제곱오차(Mean Squared Error)가 나온다. 아래의 수식의 N은 데이터 셋이 몇개인지 센 값이고 y는 관찰 값(진짜 데이터 값)이고 prediction(x)는 우리가 학습시킨 모델의 해당 input의 예측 값이다(이 수식은 사실 통계를 조금 배운 사람, 논문 조금 읽어본 사람이면 빨리 이해할 거라고 생각한다).

- 평균제곱오차(MSE)는 머신러닝에 종종 이용되지만 모든 상황에 항상 적용되는 알맞은 Loss Function은 아니다. 다른 Loss Function이 더 모델 오차 측정에 적합할 때도 많다.
Loss 줄이기, 더 정확한 모델 만드는 법
더 정확한 모델을 만드는 법은 간단하다. Loss 값을 줄이면 된다. Loss 값이 최소일 때가 가장 이상적인 모델이 완성되므로 모델의 Loss 값이 뭔지 계속 측정하는 것은 중요하며 최소의 Loss 값을 가지도록 우리가 만드는 모델의 변수(weights, bias 값)들을 조정해야한다.
Loss 값을 줄여가는 여정에서 적합한 보폭(step size 또는 learning rate)를 가지는 것도 중요하다. 보폭에 따라 더 정확한 모델을 만들기 위해 걸리는 시간, 그 정확도가 달라진다. 보폭이 너무 작은 경우, 정확한 모델을 만들기 위해 너무나 많이 학습을 시켜야하기 때문에 시간이 많이 걸린다. 하지만 또 보폭이 너무 큰 경우, 정확한 모델을 만들기 어려워진다.
따라서 Loss 값이 최소인 최대한 정확한 모델을 만들기 위해서는 적합한 보폭을 설정하는 것이 중요하다.



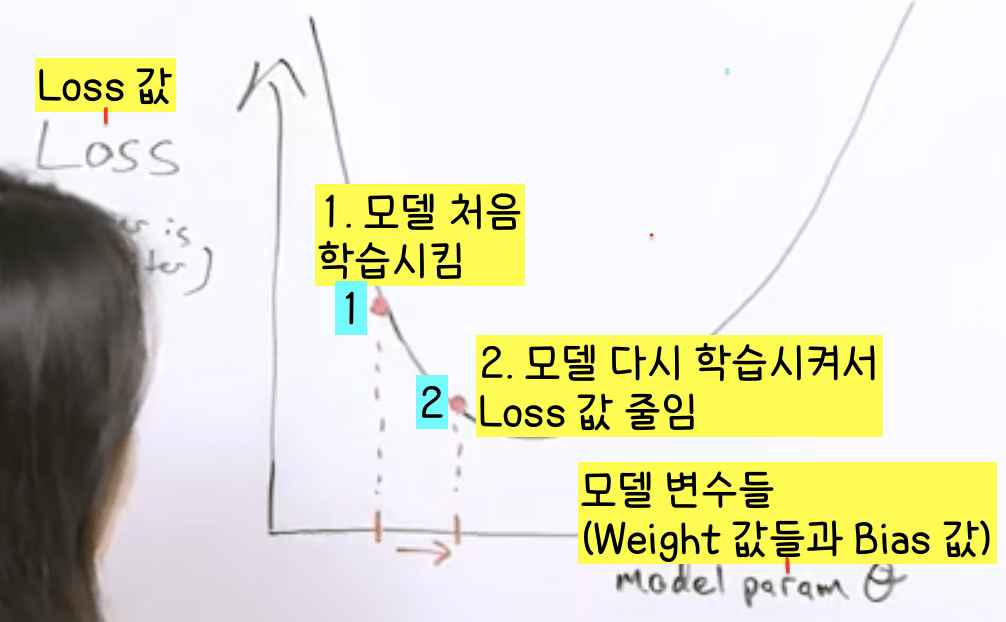
- 우리가 지금까지 본 Loss Function은 아래로 볼록한 함수였지만! 현실적인 Loss Function은 아래로 볼록한 함수가 아닌 계란 포장 용기 같은 오목 볼록 오목한 함수일 때가 많다. 따라서 최소 값이 두개 이상일 경우가 많다.


최소 값이 두개 이상인 Loss Function의 경우 맨 처음 학습한 모델의 변수(weights, bias 값)들이 우리가 도달하는 최소 값을 크게 좌우하므로 처음부터 다양한 모델들을 만드는 것이 중요하다(위의 그림 속 최소 값 1 근처에서 시작한 모델 학습과 최소 값 2 근처에서 시작한 모델 학습이 다른 결과를 나타낸다. 따라서 처음부터 다양한 변수 값을 가진 모델을 만들어 그 모델들이 각각 최소 값에 수렴하는지 봐서 가장 Loss 값이 작은 최소 값이 어떤 건지 알아내는 방법을 이용한다, 이 부분은 추후에 또 설명).
TensorFlow 기초 라이브러리 익숙해지기
이제 머신러닝 소프트웨어 TensorFlow에서 자주 쓰이는 라이브러리에 대해 알아보겠다. TensorFlow를 실행하는데 기초 중 기초이기 때문에 알아두고 익숙해지는 게 중요하다.
1. Numpy
Numpy는 데이터의 배열과 Linear Algebra(선형대수학)를 쉽고 간단하게 만드는 파이썬 라이브러리다. 머신러닝에서 엄청 많이 쓰인다. Numpy 라이브러리가 어떻게 코드로 쓰여지는지 한번 적어보고 설명해보겠다(아래 링크에 나와있는 코드를 적고 설명하는 겁니다).
import numpy as np
: Numpy 라이브러리를 쓰기 위해 Numpy 라이브러리를 np로 먼저 규정함
one_dimensional_array = np.array([1.2, 2.4, 3.5, 4.7, 6.1, 7.2, 8.3, 9.5])
print(one_dimensional_array)
: Numpy 라이브러리를 이용해 직접 데이터를 골라 배열을 만듦, 저 print(one_dimensional_array)의 결과 값은 [1.2 2.4 3.5 4.7 6.1 7.2 8.3 9.5]로 나옴
sequence_of_integers = np.arrange(5, 12)
print(sequence_of_integers)
: Numpy 라이브러리를 이용해 5이상 12미만 값들로 이루어진 배열을 만듦. 저 print(sequence_of_integers) 결과 값은 [5 6 7 8 9 10 11]임.
random_integers_between_50_and_100 = np.random.randint(low = 50, high = 101, size = (6))
print(random_integers_between_50_and_100)
: Numpy 라이브러리를 이용해 랜덤하게 데이터를 만듦(이 경우 최소 50, 최대 101, 데이터 수 6개의 데이터 셋을 만듦, .randint이므로 Integer(정수값)만으로 데이터가 구성됨). 저 print(random_integers_between_50_and_100)의 결과 값은 [69 82 87 89 59 87]로 나옴. 결과 값은 랜덤하게 형성됨. 직접 google colaboratory에서 돌려보면 다른 값이 나올 수 있음.
random_floats_between_0_and_1 = np.random.random([6])
print(random_floats_between_0_and_1)
: Numpy 라이브러리를 이용해 0과 1 사이 float(소수점을 가지는 숫자)값들을 랜덤하게 6개 뽑아서 데이터 셋을 만듦. 저 print(random_floats_between_0_and_1은 [0.75921454 0.51139789 0.71004682 0.61298316 0.3664024 0.63016914]로 나옴. 결과 값은 랜덤하게 형성됨. 직접 google colaboratory에서 돌려보면 다른 값이 나올 수 있음.
Numpy 라이브러리 활용 예시
1. 6에서 12까지의 숫자를 Numpy 라이브러리를 이용해서 배열을 만들고 그 이름을 feature이라고 짓는다, 그 이후 feature을 x3한 후(3은 weight 값) +4한 값(4는 bias 값)을 label이라고 정한다. 매우 작게 간소화시킨 머신러닝 모델을 만들어보자.
feature = np.arrange(6, 21)
print(feature)
label = 3 * feature + 4
print(label)
여기서 print(feature)은 [ 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 ]이며 print(label)은 [22 25 28 31 34 37 40 43 46 49 52 55 58 61 64]이다.
2. 우리의 데이터를 좀 더 현실적이게 만들기 위해 노이즈를 추가해보자(현실적인 상황에서는 데이터에 항상 노이즈, 오차가 있다). 노이즈는 float값으로 -2와 2 사이에 속하는 머신러닝을 만들어보자 (1번 예시를 먼저 한 후 이 코드를 돌려야 합니다. 노이즈를 이미 만들어놓은 모델, 저 label에 집어 넣는 거니까요.)
noise = (np.random.random([15]) * 4) -2
print(noise)
label = label + noise
print(label)

위의 모든 코드들은 이 링크에서 확인하실 수 있습니다. 직접 해보는 것만큼 빨리 느는 방법이 없으니 꼭 한번 해보세요! 오래 안걸려요 코딩 기초 지식이 있으신 분이라면.
2. Pandas
Pandas는 데이터들을 분류/네이밍하는 역할(Dataframing)을 하는 파이썬 라이브러리다. 보통 Numpy로 데이터 셋을 만들고 Pandas로 데이터를 사용가능하게 분류/네이밍한다. 코드를 적어보며 어떤 식으로 Pandas가 활용되는지 살펴보자!
import numpy as np
import pandas as pd
: Numpy와 Pandas 라이브러리를 불러오고 또 쉽게 사용가능하게 Numpy는 np로 설정, Pandas는 pd로 설정한다.
my_data = np.array([0, 3], [10, 7], [20, 9], [30, 14], [40, 15])
my_column_names = [‘temperature’, ‘activity’]
my_dataframe = pd.DataFrame(data=my_data, columns=my_column_names)
print(my_dataframe)
: 데이터를 Numpy로 만들고 그 데이터에 설명을 부여하기 위해 Pandas로 열마다 이름을 부여한다(my_column_name ‘temperature’, ‘activity’ 설정). print(my_dataframe)을 하면 아래의 결과가 나온다.

my_dataframe[“adjusted”] = my_dataframe[“activity”] + 2
print(my_dataframe)
: Pandas를 이용해 원래 있던 데이터에 다른 데이터를 추가할 수도 있다. 위의 코드는 activity의 +2한 값을 adjusted로 새롭게 만들겠다는 코드다. print(my_dataframe)을 하면 아래의 결과가 나온다.

print(my_dataframe.head(3), ‘\n’)
print(my_dataframe.iloc[[2]], ‘\n’)
print(my_dataframe[1:4], ‘\n’)
print(my_dataframe[‘temperature’])
: Pandas를 이용해 만든 데이터를 다양한 방법으로 추출할 수 있다. .head(n)은 n-1행까지 데이터를 추출하겠다는 거고(여기서 n은 정수를 뜻함), .iloc[[n]]은 n행의 데이터를 추출하겠다는 거다(iloc은 integer location의 약자로 특정 정수 자리의 데이터를 추출하겠다는 뜻). 같은 원리로 .iloc[a:b]는 a행부터 b-1행까지의 데이터를 추출하겠다는 것이다. [‘column name’]은 특정 열의 값을 추출하겠다는 것이다(여기서 my_dataframe[‘temperature’]은 우리의 데이터에서 ‘temperature’열 데이터를 추출하겠다는 뜻).

Pandas 라이브러리 활용 예시
1. 3×4(3행4열) Pandas Dataframe을 만들고 열의 이름을 Eleanor, Chidi, Tahani, Jason으로 짓는다. Dataframe 안 데이터는 0과 100사이의 정수를 랜덤하게 넣어보자. 그리고 전체 Dataframe과 Eleanor열의 첫번째 행렬을 읽어보자(print). 마지막으로 Tahani와 Jason의 값을 더한 5번째 열을 Janet이라는 이름으로 만들어보자!

