합성 데이터(Synthetic Data)를 이용한 Linear Regression
(*합성데이터 = 실제 데이터가 아닌 컴퓨터가 만든 데이터)
머신러닝에 사용할 라이브러리 가져오기(import)
import pandas as pd #pandas는 데이터 분류/네이밍을 위한 라이브러리.
import tensorflow as tf #tensorflow는 딥러닝을 하는데 사용하는 라이브러리.
from matplotlib import pyplot as plt #matplotlib는 데이터로 그래프를 그리는데 사용되는 라이브러리.
데이터를 학습시킬 모델 만들기
def build_model(my_learning_rate): #학습할 모델을 만드는 function
model = tf.keras.models.Sequential() #Sequential한 빈 모델을 만듦
model.add(tf.keras.layers.Dense(units=1,input_shape=(1,))) #모델에 하나의 뉴런을 가진 hidden layer 형성
model.compile(optimizer=tf.keras.optimizers.RMSprop(lr=my_learning_rate),loss=”mean_squared_error”,metrics=[tf.keras.metrics.RootMeanSquaredError()]) #모델의 학습방식 설정
return model #학습한 모델 가져옴
<Keypoint>
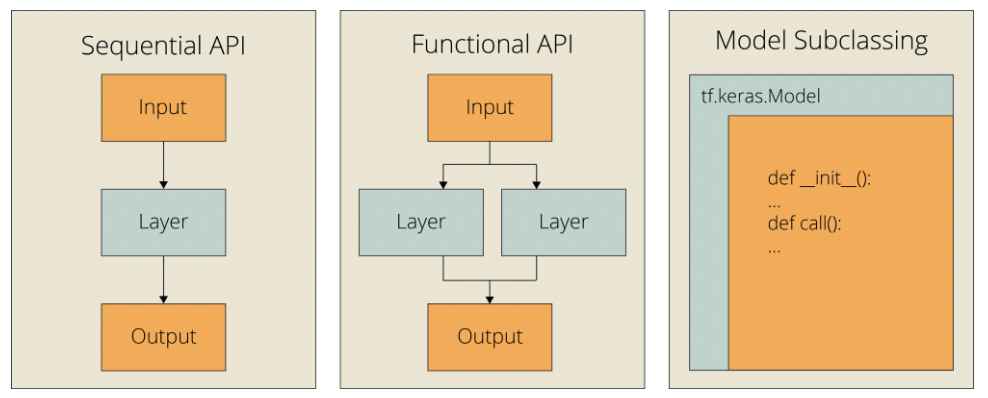
- Sequential: 가장 간단한 모델 형태(단일 Layer가 hidden layer로 쌓이는 것).
- Functional(단일하지 않은 Layer가 hidden layer로 쌓이는 것), Subclassing 모델도 존재 (아래 그림 1 참조)
- Units: 해당 Layer안에 있는 뉴런의 수 (아래 그림 2 참조)
- Input_shape: 해당 Layer의 Input 형태
- RMSprop: loss를 줄이고 더 정확한 모델을 만드는 과정에서 어떤 식으로 모델을 학습시킬 건지 결정하는 최적화 방법 중 하나.
- Optimizer(최적화 방법)는 RMSprop, SGD, Adam, Adadelta, Adagrad, Adamax, Nadam, Ftrl이 있음. 다 다른 방법으로 loss function에서 최소 값을 찾으며 모델을 학습시키며 잘못된 최적화 방법을 찾으면 모델의 정확도가 떨어지므로 우리에게 적합한 최적화 방법을 잘 골라야 함(최적화 방법에 대해서는 추후에 또 포스팅하겠음).

모델 학습시키는 function 만들기
def train_model(model, feature, label, epochs, batch_size): #모델 학습시키는 function
history = model.fit(x=feature,y=label,batch_size=batch_size,epochs=epochs) #데이터를 넣어주고 모델 학습시키기
trained_weight = model.get_weights()[0] #학습이 끝난 모델의 비중 값
trained_bias = model.get_weights()[1] #학습이 끝난 모델의 편향 값
epochs = history.epoch #학습이 끝난 모델이 전체 데이터 셋을 몇번이나 처음부터 끝까지 학습했는지, 그 횟수가 epochs
hist = pd.DataFrame(history.history)
rmse = hist[“root_mean_squared_error”] #학습이 끝난 모델이 어떤 방식으로 학습했는지(어떤 식으로 loss를 줄여나갔는지), 각각의 epoch마다 root_mean_squared_error구함
return trained_weight, trained_bias, epochs, rmse #학습을 끝난 모델의 중요한 정보들 가져옴(위에 나열한 값들)
Feature, Label 그래프 만들기 (matplotlib 사용)
def plot_the_model(trained_weight, trained_bias, feature, label): #모델 그래프 만드는 function
plt.xlabel(“feature”) #x축 feature(input)값으로 설정
plt.ylabel(“label”) #y축 label(output)값으로 설정
plt.scatter(feature, label) #(x,y)값 그래프에 그리기
x0 = 0
y0 = trained_bias #[x0,y0] = [0,편향(bias)]
x1 = feature[-1]
y1 = trained_bias + (trained_weight * x1) #[x1,y1] = [x1, 비중(weight)*x1(input)+편향(bias)]
plt.plot([x0, x1], [y0, y1], c=’r’) # [x0,y0]에서 [x1,y1]를 잇는 빨간 선 그래프 그리기(c는 color, r은 red 뜻)
plt.show() #전체 그래프 보여주기

Loss 그래프 만들기 (matplotlib 사용)
def plot_the_loss_curve(epochs, rmse): #Loss 그래프 만드는 function
plt.figure() #그래프 그릴 영역 확보
plt.xlabel(“Epoch”) #x축 epoch값으로 설정
plt.ylabel(“Root Mean Squared Error”) #y축 rmse값으로 설정
plt.plot(epochs, rmse, label=”Loss”) #Loss 그래프 그리기
plt.legend() #범례 형성
plt.ylim([rmse.min()*0.97, rmse.max()]) #y축 영역 정하기(y최소 값: rmse.min()*0.97, y최대 값: rmse.max())
plt.show() #전체 그래프 보여주기

모델을 학습시킬 데이터 셋 만들기
my_feature = ([1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0, 11.0, 12.0])
my_label = ([5.0, 8.8, 9.6, 14.2, 18.8, 19.5, 21.4, 26.8, 28.9, 32.0, 33.8, 38.2])
모델 학습시키기 & Feature, Label 그래프 그리기 & Loss 그래프 그리기 & 분석
learning_rate=0.01 #학습 속도(=step size)
epochs=10 #모든 데이터 셋을 몇번이나 학습시키는지, 그 횟수
my_batch_size=12 #한번 학습시킬 때 몇개의 데이터를 넣는지
my_model = build_model(learning_rate) #모델 만들기(위에 언급한 build_model function 사용)
trained_weight, trained_bias, epochs, rmse = train_model(my_model, my_feature,my_label, epochs,my_batch_size) #모델 학습시키기(위에 언급한 train_model function 사용)
plot_the_model(trained_weight, trained_bias, my_feature, my_label) #plot_the_model 함수 불러오기(Feature, Label 그래프 그리기)
plot_the_loss_curve(epochs, rmse) #plot_the_loss_curve 함수 불러오기(Loss 그래프 그리기)

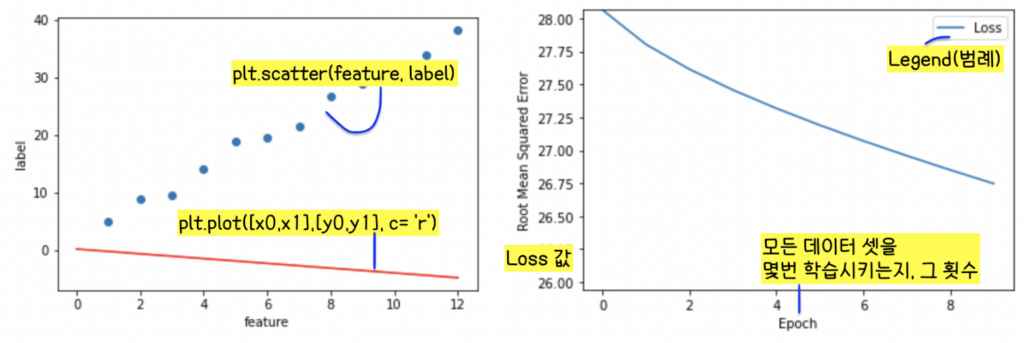
분석: 모델을 learning rate가 0.01이고 epochs가 10이고 batch_size가 12로 학습시키면
- 그림 3 왼쪽 그래프처럼 데이터와 모델 학습된 결과가 동떨어지고(파란 점: 데이터들, 빨간 선: 모델이 학습한 결과, 빨간 선이 파란 점들의 행동 양식을 보여주지 못한다. 데이터 학습 실패, 모델 정확도 떨어짐)
- 그림 3 오른쪽 그래프처럼 Loss값이 학습을 끝내도 너무 높고 특정 값에 수렴하지 않는다(모델 학습 시작 때 Loss값이 28을 좀 넘었는데 학습을 마친 후 26.75정도가 되었다. Loss값이 별로 줄어들지 않았으며 어떤 값에 수렴하지 않았다, 모델 정확도 떨어진다는 뜻).
-> learning rate, epochs, batch size를 변화시키며 모델 정확도를 올려야 한다. 하나하나 조금씩 건드려보자!
정확도 높은 모델을 만들기 위해 Epochs 값을 올려보자!
learning_rate=0.01
epochs=450
my_batch_size=12
my_model = build_model(learning_rate)
trained_weight, trained_bias, epochs, rmse = train_model(my_model, my_feature, my_label, epochs, my_batch_size)
plot_the_model(trained_weight, trained_bias, my_feature, my_label)
plot_the_loss_curve(epochs, rmse)
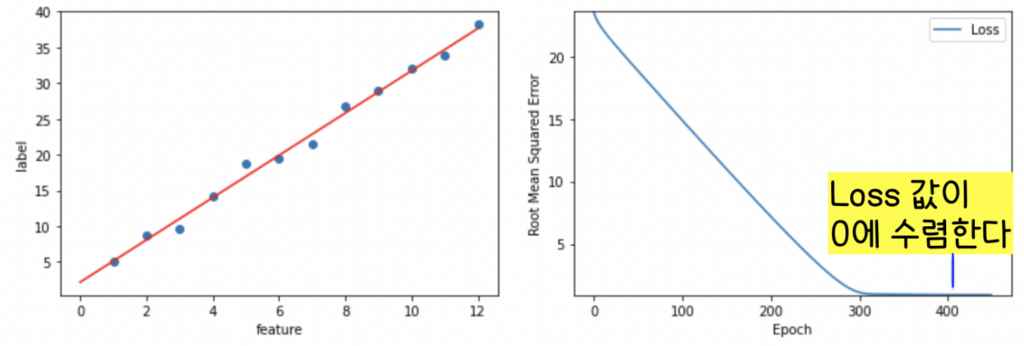
분석
Epoch를 10에서 450로 모델 학습 횟수를 올렸더니(그림 3, 그림 4 비교) 모델의 정확도가 크게 올라갔다. 빨간선(모델의 학습결과)이 데이터의 행동양식을 잘 설명할 수 있게 되었으며 그 결과로 Loss 값이 0으로 plateau(특정 값에 수렴)되는 걸 볼 수 있다.
Epoch이 너무 작으면 모델 학습에 부정적 영향을 준다는 것을 확인할 수 있다.
이번엔 Learning Rate를 높여보면 어떨까?
learning_rate=100
epochs=450
my_model = build_model(learning_rate)
trained_weight, trained_bias, epochs, rmse = train_model(my_model, my_feature, my_label, epochs, my_batch_size)
plot_the_model(trained_weight, trained_bias, my_feature, my_label)
plot_the_loss_curve(epochs, rmse)
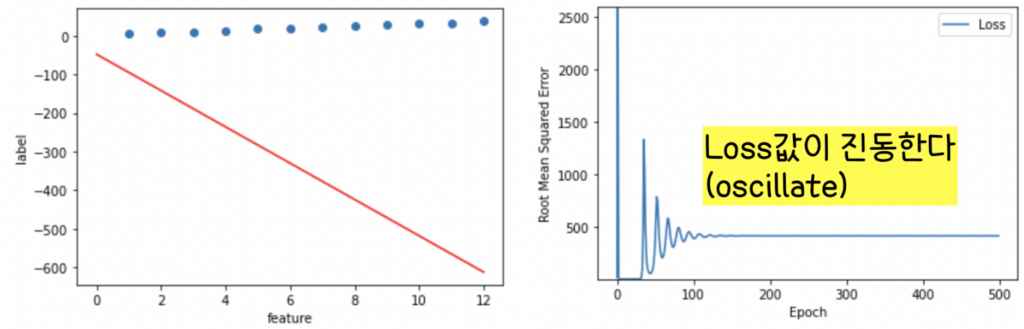
분석
Epoch가 450인 상태에서 이번엔 Learning Rate를 올려보자. 어머나! 이것은 잘못된 판단이었군,,ㅜ 빨간선(학습 결과)와 데이터가 또 따로 논다. 그리고 Loss값이 진동한다.
이 경우 모델 학습에 실패했다는 것이고 loss 값이 진동한다는 것은 learning rate(학습 속도, step size)가 너무 크다는 걸 의미한다. Learning Rate가 너무 크면 모델 학습에 부정적인 영향을 준다는 걸 확인할 수 있다.
여기서 우리는 알 수 있다. 적절한 Epoch과 Learning Rate가 모델 학습에 꼭 필요하다는 것을!
적절한 Epoch과 Learning Rate를 가진 모델을 만들어보자.
learning_rate=0.14
epochs=70
my_batch_size=12
my_model = build_model(learning_rate)
trained_weight, trained_bias, epochs, rmse = train_model(my_model, my_feature, my_label, epochs, my_batch_size)
plot_the_model(trained_weight, trained_bias, my_feature, my_label)
plot_the_loss_curve(epochs, rmse)
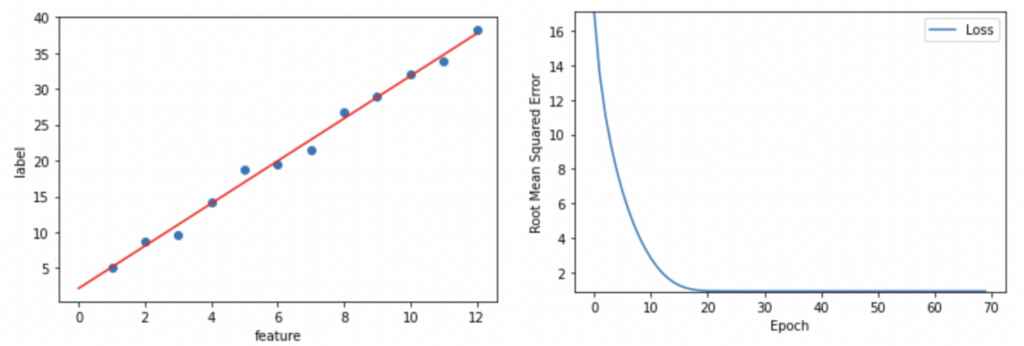
분석
learning_rate 0.01, epochs 450 였을 때도 모델 학습에 성공했지만(그림 4) 이번에도(learning_rate 0.14,
epochs 70) 모델 학습에 성공했다. 하지만 엄밀히 말하면 이번이 더 최적화된 모델 학습 방법이다!!
이 경우 Learning Rate는 높고 Epoch는 낮아서 모델이 더 빠르게 데이터를 학습할 수 있다(컴퓨터의 연산 시간이 적게 걸림).
이번엔 Batch Size를 건드려볼까?
learning_rate=0.05
epochs=125
my_batch_size=1
my_model = build_model(learning_rate)
trained_weight, trained_bias, epochs, rmse = train_model(my_model, my_feature, my_label, epochs, my_batch_size)
plot_the_model(trained_weight, trained_bias, my_feature, my_label)
plot_the_loss_curve(epochs, rmse)
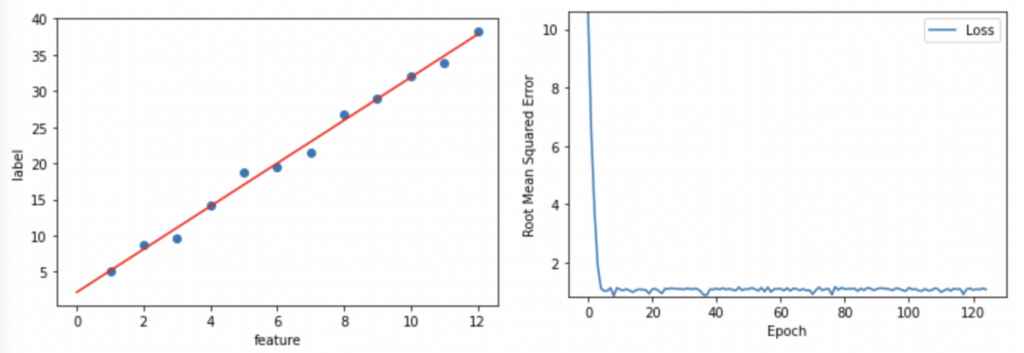
분석
Batch Size * Batch = Full Data Size(이해가 안되면 이 글을 보세요).
Batch Size가 작을수록 Batch가 커진다. Batch는 iteration과 같으며 매 iteration마다 모델 학습의 편향(bias)와 비중(weight)가 달라진다.
만약 Batch Size가 6이라면 매 6개의 examples마다 loss 값을 구하고 그에 따라 모델의 편향과 비중 값을 적절하게 바꾼다.
그냥 Batch Size를 우리의 데이터 셋 수(examples 수)로 정할 수도 있지만 Batch Size를 줄이면 모델 학습 시간이 단축된다. 하지만 Batch Size가 너무 작으면 모델 학습에 실패하고 정확도가 떨어지는 모델을 만들 수 있으니 유의하자.
(Batch Size가 너무 작으면 모델의 Loss값이 수렴하지 않는다.)
요약!
- Loss 값은 점차적으로 줄어들어야한다. 처음에는 가파르게 줄어들다가 나중에는 천천히 줄어들어야 하며 결국엔 0에 수렴해야 한다.
- Loss 값이 0에 수렴하지 않으면 epoch 수를 늘려보자
- Loss 값이 처음부터 너무 작게 줄어들면 Learning Rate를 늘려보자(하지만 Learning Rate가 너무 크면 또 Loss 값이 수렴하지 않게되니 유의, Loss 값 진동하게 됨!).
- Learning Rate를 낮추며 Epoch와 Batch Size를 높이는 것은 종종 좋은 모델 학습 방법일 수 있음(절대적인 것 아님, 상황마다 다름).
- Batch Size가 너무 작으면 모델 학습에 실패할 수 있음. 처음엔 Batch Size를 크게 시작하되 점점 작게 Batch Size를 넣어보는 걸 추천
- 현실 세계의 진짜 데이터 셋 같은 경우 데이터 수가 너무 방대하므로(examples 수 많음), 전체 데이터 셋이 메모리 안에 안 들어갈 수 있음. 이 경우 Batch Size를 줄여서 메모리 안에 데이터 셋을 넣을 수 있게 해야함.
- (★★★) 모든 hyperparameter(Learning Rate, Epoch, Batch Size 등)은 학습하고자 하는 데이터에 맞춰 그 값을 설정해야 함. 계속 자신이 가지고 있는 데이터를 가지고 정확한 모델을 만들기 위해 노력해야 함.
*오늘 공부한 자료는 여기에 있어요~ 실데이터를 이용한 Linear Regression은 여기서 보세요~