실데이터(Real Data)를 이용한 Linear Regression
저번 시간에는 합성 데이터를 이용한 Linear Regression 예시를 알아봤는데 오늘은 실데이터를 이용한 Linear Regression 예시를 알아보겠다.
머신러닝에 필요한 라이브러리 가져오기(import) + 데이터 출력 조건 설정
import pandas as pd #pandas는 데이터 분류/네이밍을 위한 라이브러리.
import tensorflow as tf #tensorflow는 딥러닝을 하는데 사용하는 라이브러리.
from matplotlib import pyplot as plt #matplotlib는 데이터로 그래프를 그리는데 사용되는 라이브러리.
pd.options.display.max_rows = 10 #출력 시 최대 10줄까지 가능
pd.options.display.float_format = “{:.1f}”.format #데이터를 소수점 한자리까지 가능하도록 설정
csv파일에 있는 데이터 불러오기
training_df = pd.read_csv(filepath_or_buffer=”https://download.mlcc.google.com/mledu-datasets/california_housing_train.csv“) #데이터 불러오기
training_df[“median_house_value”] /= 1000.0 #training_df[“median_house_value”] = training_df[“median_house_value”]/1000.0
training_df.head() #상위 5개의 행 출력

데이터 통계 출력
training_df.describe() #데이터 통계 출력

*아래의 모델 학습 부분은 여기서 더 자세히 볼 수 있습니다. 이해가 가지 않으시면 한번 읽어보세요.
데이터를 학습시킬 모델 만들기
def build_model(my_learning_rate): #학습할 모델을 만드는 function
model = tf.keras.models.Sequential() #Sequential한 빈 모델을 만듦
model.add(tf.keras.layers.Dense(units=1, input_shape=(1,))) #모델에 하나의 뉴런을 가진 hidden layer 형성
model.compile(optimizer=tf.keras.optimizers.RMSprop(lr=my_learning_rate), loss=”mean_squared_error”, metrics=[tf.keras.metrics.RootMeanSquaredError()]) #모델의 학습방식 설정
return model #학습한 모델 가져옴
모델 학습시키는 function 만들기
def train_model(model, df, feature, label, epochs, batch_size): #모델 학습시키는 function
history = model.fit(x=df[feature], y=df[label], batch_size=batch_size, epochs=epochs) #데이터를 넣어주고 모델 학습시키기
trained_weight = model.get_weights()[0] #학습이 끝난 모델의 비중 값
trained_bias = model.get_weights()[1] #학습이 끝난 모델의 편향 값
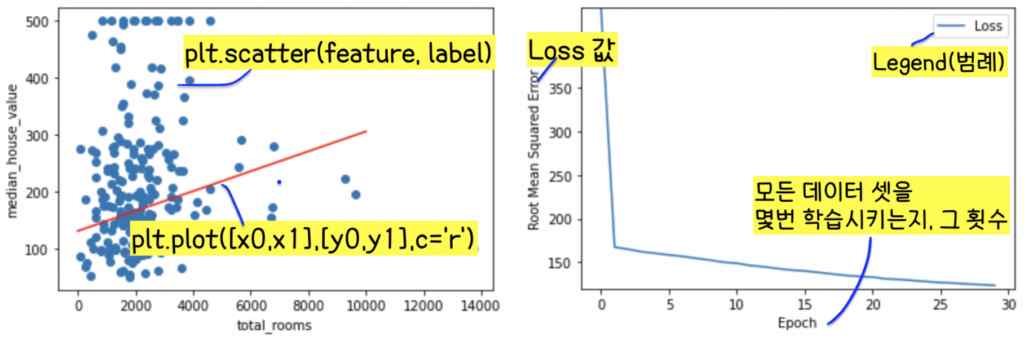
epochs = history.epoch #학습이 끝난 모델이 전체 데이터 셋을 몇번이나 처음부터 끝까지 학습했는지, 그 횟수가 epochs
hist = pd.DataFrame(history.history)
rmse = hist[“root_mean_squared_error”] #학습이 끝난 모델이 어떤 방식으로 학습했는지(어떤 식으로 loss를 줄여나갔는지), 각각의 epoch마다 root_mean_squared_error구함
return trained_weight, trained_bias, epochs, rmse #학습을 끝난 모델의 중요한 정보들 가져옴(위에 나열한 값들)
Feature, Label 그래프 만들기 (matplotlib 사용)
def plot_the_model(trained_weight, trained_bias, feature, label): #모델 그래프 만드는 function
plt.xlabel(feature) #x축 feature(input)값으로 설정
plt.ylabel(label) #y축 label(output)값으로 설정
random_examples = training_df.sample(n=200) #랜덤한 데이터들로 200개의 행 추출
plt.scatter(random_examples[feature], random_examples[label]) #(x,y)값 그래프에 그리기
x0 = 0
y0 = trained_bias #[x0,y0] = [0,편향(bias)]
x1 = 10000
y1 = trained_bias + (trained_weight * x1) #[x1,y1] = [x1, 비중(weight)*x1(input)+편향(bias)]
plt.plot([x0, x1], [y0, y1], c=’r’) # [x0,y0]에서 [x1,y1]를 잇는 빨간 선 그래프 그리기(c는 color, r은 red 뜻)
plt.show() #전체 그래프 보여주기
Loss 그래프 만들기 (matplotlib 사용)
def plot_the_loss_curve(epochs, rmse): #Loss 그래프 만드는 function
plt.figure() #그래프 그릴 영역 확보
plt.xlabel(“Epoch”) #x축 epoch값으로 설정
plt.ylabel(“Root Mean Squared Error”) #y축 rmse값으로 설정
plt.plot(epochs, rmse, label=”Loss”) #Loss 그래프 그리기
plt.legend() #범례 형성
plt.ylim([rmse.min()*0.97, rmse.max()]) #y축 영역 정하기(y최소 값: rmse.min()*0.97, y최대 값: rmse.max())
plt.show() #전체 그래프 보여주기

방 수를 feature로 잡고 모델 학습시키기 + Feature, Label 그래프 그리기 + Loss 그래프 그리기 + 학습시킨 모델로 예측해보기(모델 정확도 확인)
learning_rate = 0.01
epochs = 30
batch_size = 30
my_feature = “total_rooms” #feature을 “total rooms”로 잡고
my_label=”median_house_value” #label을 “median house value”로 잡음
my_model = None #모델 초기화
my_model = build_model(learning_rate) #모델 만들기
weight, bias, epochs, rmse = train_model(my_model, training_df,my_feature, my_label,epochs, batch_size) #모델 학습시키기
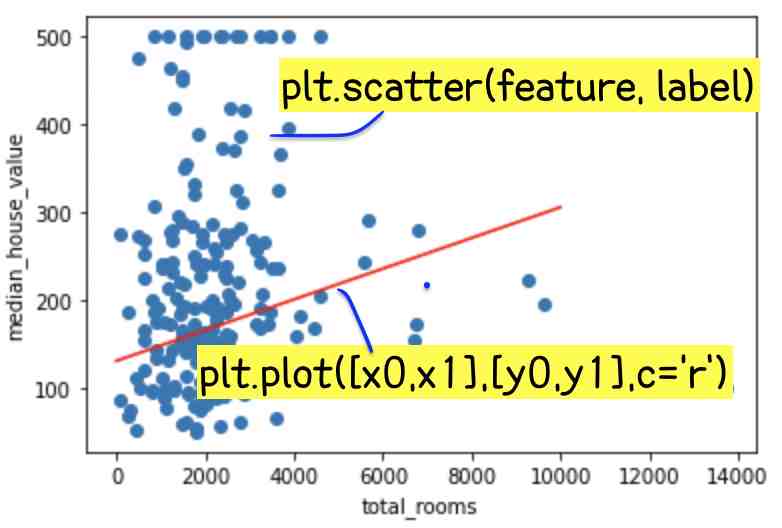
plot_the_model(weight, bias, my_feature, my_label) #feature, label 그래프 그리기
plot_the_loss_curve(epochs, rmse) #loss값 그래프 그리기

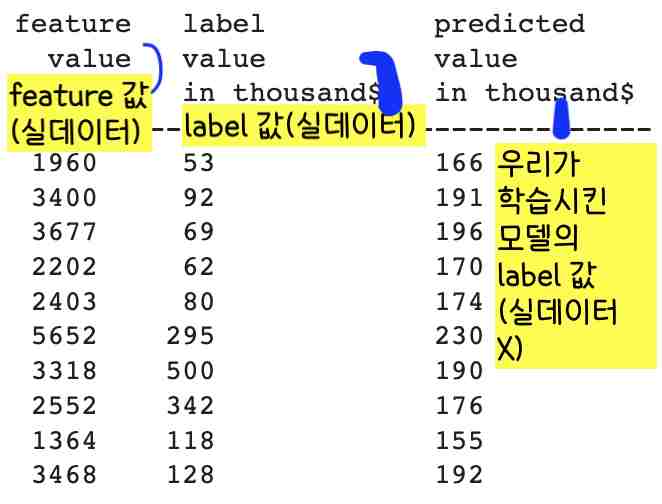
학습시킨 모델로 데이터 예측해보기, 학습시킨 모델의 정확도 확인
def predict_house_values(n, feature, label):
batch = training_df[feature][10000:10000 + n] #10000에서 10000+n번째 데이터의 feature 값을 batch로 가지고 온다.
predicted_values = my_model.predict_on_batch(x=batch) #위의 batch를 우리가 만든 모델에 넣었을 때 어떤 label값을 도출하는지 데이터로 도출.
print(“feature label predicted”)
print(” value value value”)
print(” in thousand$ in thousand$”)
print(“————————————–“)
for i in range(n):
print (“%5.0f %6.0f %15.0f” % (training_df[feature][10000 + i], #10000에서 10000+n번째 데이터의 feature값 뽑기.
training_df[label][10000 + i], #10000에서 10000+n번째 데이터의 label값 뽑기(원래 데이터, 실데이터).
predicted_values[i][0] )) #10000에서 10000+n번째 데이터의 label값 뽑기(우리가 학습시킨 모델에 위의 batch, feature값을 넣었을 때)
predict_house_values(10, my_feature, my_label) #위의 함수 실행
분석
그림 1과 표 1를 보면 우리가 학습시킨 모델의 정확도가 높지 않고 모델 학습에 실패했다는 것을 알 수 있다.
(그림 1 오른쪽을 보면 저 빨간 선이 데이터의 행동양식을 잘 표현하지 않고 또 왼쪽의 loss 값 그래프를 보면 loss 값이 0에 수렴하지 않고 학습을 마친 후에도 높다는 것을 볼 수 있다. 표 1의 label 값(두번째 열)과 predicted value in thousands(세번째 열)도 크게 차이난다는 것을 확인할 수 있다.)
이걸로 1.) 우리가 뽑은 10개의 데이터(batch)가 모델 학습에 적합하지 않거나(우리가 뽑은 10개의 데이터가 모든 데이터를 대변하는 데이터가 아닐 수 있다), 2.)우리가 feature값으로 정한 total rooms가 label인 median house value값에 크게 영향을 미치지 않을 수 있다는 걸 조심스럽게 추측해볼 수 있다.
이런 추측을 기반으로 모델 학습을 이어가보자.
집에서 사는 사람 수를 feature로 잡고 모델 학습시키기 + Feature, Label 그래프 그리기 + Loss 그래프 그리기 + 학습시킨 모델로 예측해보기(모델 정확도 확인)
my_feature = “population” #feature을 방 수에서 집에서 사는 사람 수로 바꾸었다.
learning_rate = 0.05
epochs = 18
batch_size = 3
my_model = build_model(learning_rate) #모델 만들기
weight, bias, epochs, rmse = train_model(my_model, training_df, my_feature, my_label, epochs, batch_size) #모델 학습시키기
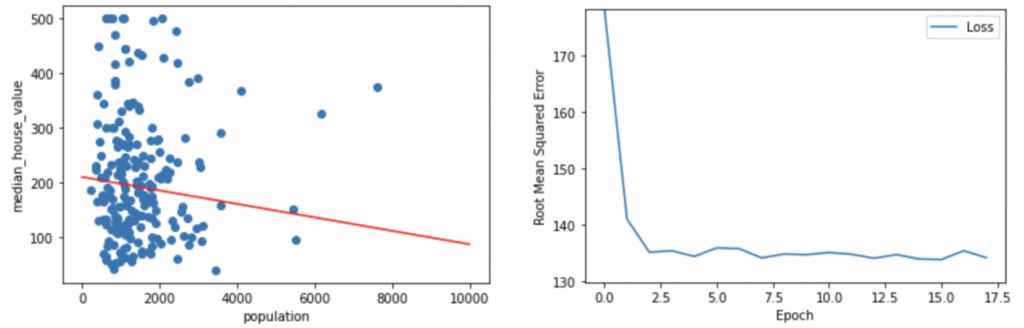
plot_the_model(weight, bias, my_feature, my_label) #feature, label 그래프 그리기
plot_the_loss_curve(epochs, rmse) #Loss 그래프 그리기
predict_house_values(10, my_feature, my_label) #함수 실행

분석
그림 2과 표 2를 보면 우리가 학습시킨 모델의 정확도가 높지 않고 또 모델 학습에 실패했다는 것을 알 수 있다.
(그림 2 오른쪽을 보면 저 빨간 선이 데이터의 행동양식을 잘 표현하지 않고 또 왼쪽의 loss 값 그래프를 보면 loss 값이 0에 수렴하지 않고 학습을 마친 후에도 높다는 것을 볼 수 있다. 표 2의 label 값(두번째 열)과 predicted value in thousands(세번째 열)도 크게 차이난다는 것을 확인할 수 있다.)
이걸로 우리가 feature값으로 정한 population이 label인 median house value값에 크게 영향을 미치지 않을 수 있다는 걸 또 추측해볼 수 있다.
한명당 쓰는 방 수(방 수/집에서 사는 사람 수)를 feature로 잡고 모델 학습시키기 + Loss 그래프 그리기 + 학습시킨 모델로 예측해보기(모델 정확도 확인) <Feature을 합성해서 만들어보자!, Synthetic Feature>
training_df[“rooms_per_person”] = training_df[“total_rooms”] / training_df[“population”]
my_feature = “rooms_per_person” #feature을 방 수/집에서 사는 사람 수로 바꿈.
learning_rate = 0.06
epochs = 24
batch_size = 30
my_model = build_model(learning_rate) #모델 만들기
weight, bias, epochs, mae = train_model(my_model, training_df, my_feature, my_label, epochs, batch_size) #모델 학습시키기
plot_the_loss_curve(epochs, mae) #Loss 그래프 그리기
predict_house_values(15, my_feature, my_label) #함수 실행
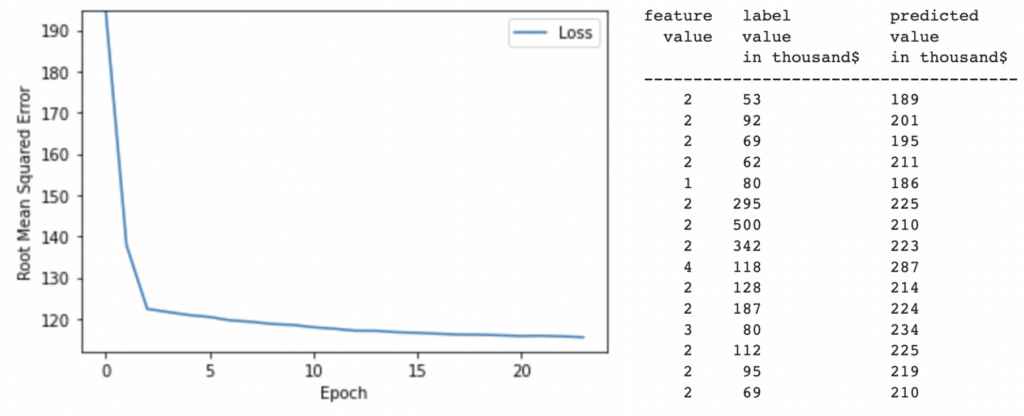
분석
그림 3과 표 3를 보면 우리가 학습시킨 모델의 정확도가 높지 않고 또 다시 한번! 모델 학습에 실패했다는 것을 알 수 있다.
(그림 3 loss 값 그래프를 보면 loss 값이 0에 수렴하지 않고 학습을 마친 후에도 높다는 것을 볼 수 있다. 표 3의 label 값(두번째 열)과 predicted value in thousands(세번째 열)도 크게 차이난다는 것을 확인할 수 있다.)
이걸로 우리가 feature값으로 정한 room per person(total rooms/population)도 label인 median house value값에 크게 영향을 미치지 않을 수 있다는 걸 또 다시 한번 추측해볼 수 있다.
이렇게 세번이나 모델 학습에 실패했다. label과 관련있는 feature값을 알아야 그대로 모델을 학습시켜서 모델의 정확도를 높일텐데,, 흠,, 어떻게 해야할까?
이건 어떨까? Correlation Matrix를 만들어보자! (=Label과 관련있는 Feature을 찾아보자!)
training_df.corr() #우리가 가지고 있는 데이터로 correlation matrix를 만들어보자.

분석
표 4를 보면 label인 median house value에서 median income의 값이 0.7로 가장 높은 것을 알 수 있다.
따라서 median income(집에서 사는 사람의 수입)을 feature로 하고 모델을 학습시키면 정확한 모델을 만들 수 있을 거 같다!
(median income을 feature로 하고 모델 학습시키는 부분은 이 글에서 생략하겠다. 시간나면 한번 스스로 만들어보셔요~)
*나중에 더 공부할텐데 median income을 feature로 하고 모델을 학습시키는 부분은 공정성과 윤리적인 부분에서 문제가 생길 수 있다고 합니다. 이 부분은 나중에 더 자세히 다룰게요!
*오늘 공부한 부분은 이 링크에서 전부 다 보실 수 있습니다. (모두에게 공개된 자료에요 ^_^)